
广义上的归因是指个体对自己、或他人的行为的原因加以解释和推测的过程。
比如A的餐厅生意兴隆,大家通常会对这件事进行这样的分析和解释:有的人说餐厅位置好,有的说菜有特色,有的说服务周到,有的说营销成功等等。但无论最终将原因归结为什么因素,这种探索原因、寻求解释的过程就是归因。 生活中,人们常常会对周围发生的事情进行归因,只是意识不到而已。
归因,对于个人而言可能影响到个人习惯、情感、成就等;而对于生意而言可谓是轻可见收益,重可见成败了。
可是在实际的操作中,归因的计算不仅对小生意而言是个挑战,对行业巨头来说也是个不小的挑战。
为了弄清楚这一问题,我们先从一个Google用过的例子看起:是什么让你决定要结婚?
转化旅程 (Conversion Journey)

如图中所示,为了简便,我们来假设这是一场闪婚模型…
- 使用约会软件
- 见面喝咖啡
- 一起看电影
- 求婚
- 结婚
好了,我们在结婚前经历了4步,那么到底哪一步让你觉得对方就是人生中的另一半呢?是喝咖啡时的风趣幽默?还是求婚时的浪漫典礼?
这怕是分歧最大的地方了。

首次触发模型(First-Touch Attribution Model)
如果你去问同样使用约会软件的朋友,她们可能会说这都是这个软件的功劳——毕竟没有它,可能这段邂逅打一开始就完全不可能发生,更别说之后的姻缘了。
这种情况在数字营销中叫作首次触发模型(First-Touch Attribution Model)
末次触发模型(Last-Touch Attribution Model)
可是,如果你问参与求婚的人,那多半会说求婚才是关键:毕竟从戒指选购,到求婚场景安排,无一都是心血的体现,更何况大家都从新娘口中听到了“Yes”这种立竿见影的反馈,所以精心策划的求婚环节才是成功的缘由。
相对地,这种情况则称作为末次触发模型(Last-Touch Attribution Model)
那么这个结婚的决定到底该归功于谁呢?
不难看出,上述的4个环节中每一个都有自己存在的理由,缺一不可。倘若没了约会APP就没有后来的咖啡厅邂逅,没了邂逅就不会有进一步在影院的发展,也就不会有之后的求婚。
再拆开来说,无论是选购婚戒,还是一开始在约会APP上指尖的每次翻页,都在促成这段因缘中起到了必不可少的作用。
那么问题来了:同样是做贡献,钻戒与在APP上翻页的比重会是一样吗?
准确的归因
在过去很长的一段时间内,首次触发模型几乎是我们唯一的选择。因为技术的原因,我们无法得知,每一个步骤为了每一次复杂冗长的转化到底贡献了多少。
现如今,技术与工具的迭代,我们增加了数种归因模型以帮助做出更准确的判断。
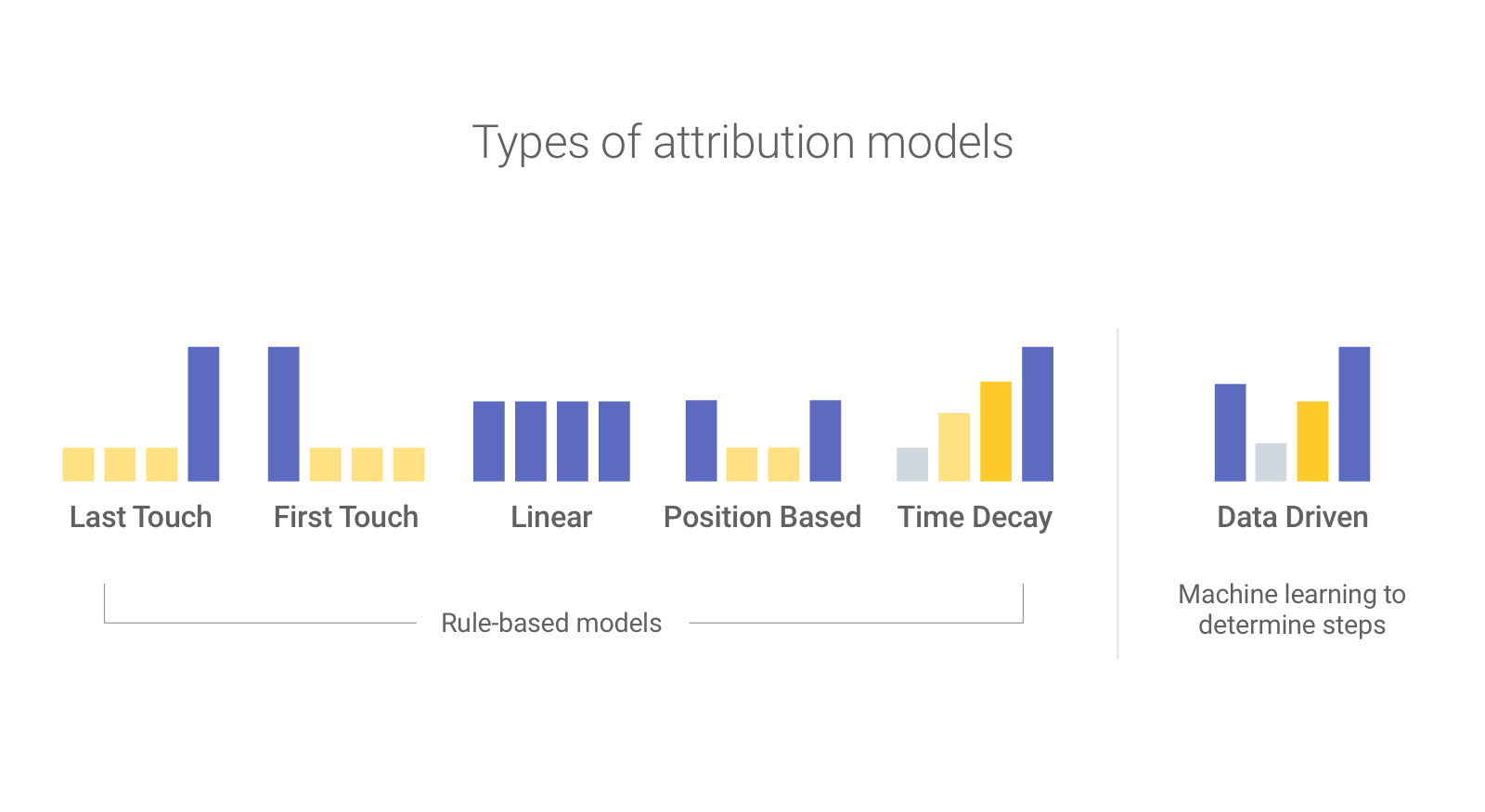
比如,线性模型(Linear),位置模型(Position Based),与时间衰减模型(Time Decay)
线性模型
线性模型,顾名思义,所有互动环节都获得完全相等的贡献。比如,想在整个营销周期(Campaign Time Frame)相对平缓地维持住品牌认知,此时间段内的每个接触点都很重要。
位置模型
位置模型,是“首次触发”与“末次触发”的结合,将首次与末次各归功40%,剩下的20%交由中间触点进行平均分配。这在品牌最看重首末两次互动时适用:你做了一次抵达营销活动(Reach Campaign)时实现了高效的人群触及,现在只想等待他们在需求来临时时检索你的品牌。
时间衰减模型
时间衰减模型,即将贡献分配给离成交点最近的接触点,适合成交决策耗时短的产品,或成交成本低的产品,如刚需产品。比如受众在电视广告上看到了一款饮料,于是在周末逛超市时刚巧看到了此款饮料在打折,便直接拿下了(这也是为什么FMCG永远是铺货最重要)。
在实际数字营销统计分析时,衰减模型基于指数衰减,并通常将7天设为默认的“半衰期(Half-life)”,即成交7天前所有触点贡献减半。也就是说,在30天的回溯期期间,首次触发点的贡献约为末次触发点1/8。
基于数据学习的归因模型(Data-Driven)
如果说上述模型都是基于人为的规则建立,数据学习的归因则是基于历史数据来预测趋势。
还是结婚的例子,数据学习归因模型会从过去的所有婚姻中找到规律,以杜绝以外的出现:是不是不去一起看场电影这婚就结不成了?婚戒上的钻戒到底该多大才能成功求婚?
如此一来,我们才能得出这样的结论:原来一起看电影占比占比10%,求婚准备占30%——其中钻石克拉数占25%。
总结
无论你用什么模型,你的商业目标都是帮助你的客户对你的产品尽快地做出高质量的决策。而归因在此帮你解决的问题应当是这样:每个接触点我该投入多少?是否要增加或精简一些环节在转化旅程中?对获取的信息是否规避了认知偏差?
而以上则是你能否将“时间与金钱花在刀刃”上的关键。


